How I Actually Use AI to Write Code (Without Wrecking the Codebase)
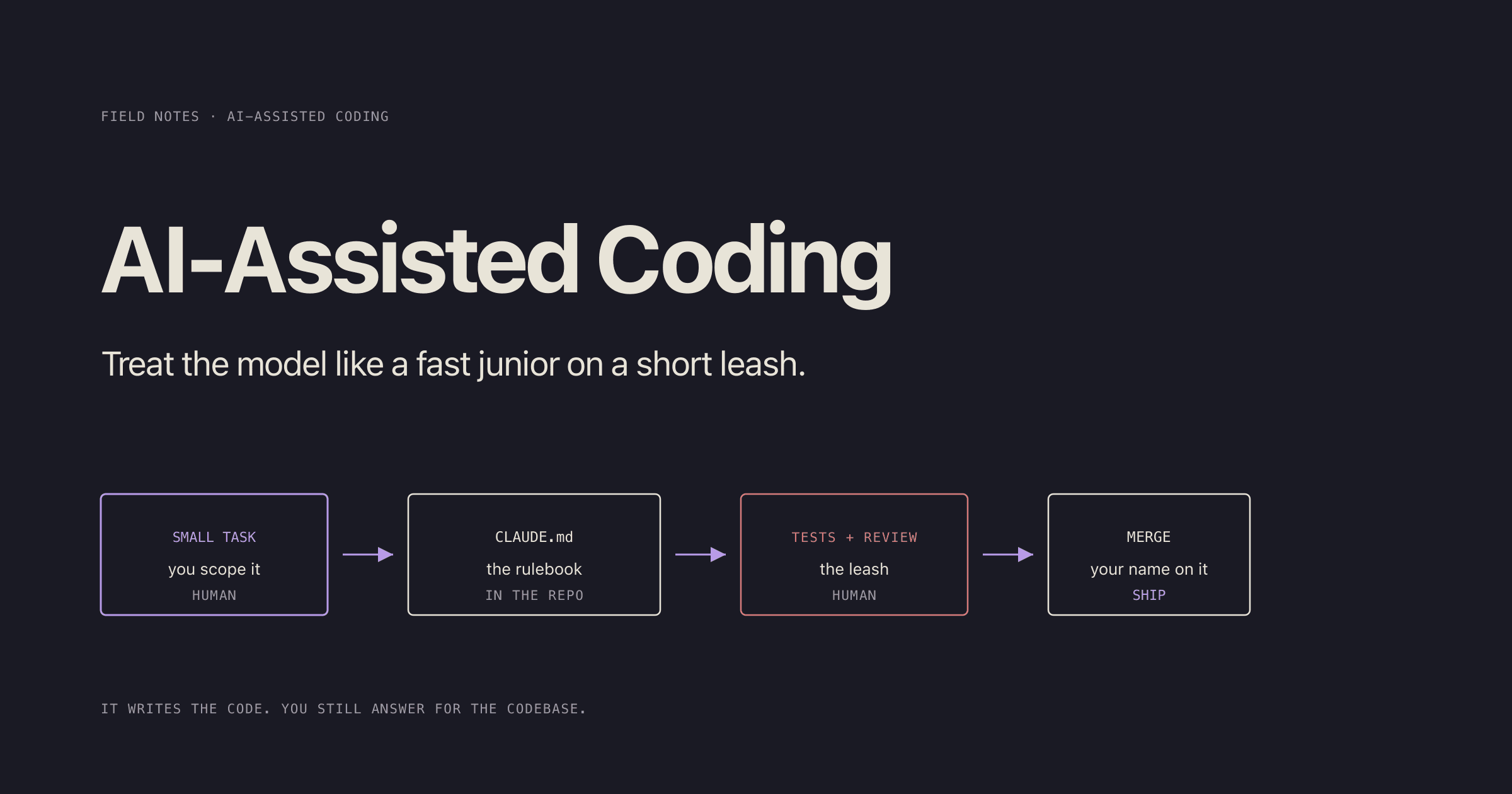
Same trick as everything else: give the model a rulebook and a leash.
AI can write code fast. It can also write a bug fast, with total confidence and a beautifully worded commit message. That's the part the demos leave out.
You've seen the videos. Someone types one sentence, an app appears, the crowd claps. What's never on camera is the next six months: the part where somebody has to read that code, change it, and explain to a customer why it did something nobody intended. Generating code was never the hard part of this job. Living with it is.
I lean on AI every day. Claude Code, Cursor, the usual suspects. But I use it the way you'd use a strong, fast junior engineer who started this morning, has read nothing, remembers nothing tomorrow, and will confidently do exactly the wrong thing if you let them. Handled like that, it's a huge multiplier. Handled like a senior you can hand the keys to, it quietly rots your codebase while everyone's impressed by the velocity.
Here's how I actually run it.
The vibe-coding trap
"Vibe coding" is fun right up to the moment it isn't. You prompt, it produces, it runs, you ship. Speed feels incredible. Then a bug shows up in code you didn't write and don't understand, and now you're debugging a stranger's work with none of the context that would've come from writing it yourself.
That's the trap. The code looking plausible is not the same as the code being correct, and AI is extremely good at plausible. It writes things that pass the eye test and fail the edge case. Confident, well-formatted, subtly wrong. The worst kind of pull request, basically, except it arrives every ninety seconds.
The fix is the same one that works for AI-assisted writing, and honestly the same one that works for junior engineers: you don't hand over a blank canvas and hope. You hand over a rulebook and a leash.

The rulebook lives in the repo
For code, the rulebook isn't a prompt you retype. It's a file that sits in the repository and the agent reads automatically every time it starts: CLAUDE.md, or AGENTS.md, or your editor's rules file. Same idea whatever the tool calls it.
Think of it as the onboarding doc you wish every new hire actually read, except this one does, every single session, without complaint.

Without it, the agent guesses. It puts files wherever, invents a naming scheme, picks a library you'd never approve, and writes business logic into a controller because nothing told it not to. With it, the guessing stops. Here's the shape of mine:
# CLAUDE.md
## Project map
- HTTP controllers live in `src/api`, thin. Business logic in `src/services`.
- Persistence in `src/repositories`. No SQL outside that folder.
## Conventions
- Constructor injection only. No field @Autowired.
- DTOs in/out at the boundary. Never leak entities to the API.
## Commands (run these, don't claim "done" until they pass)
- Build: ./mvnw -q compile
- Test: ./mvnw -q test
- Lint: ./mvnw -q spotless:check
## Do NOT
- Add a dependency without asking.
- Touch the `payments` module.
- Commit anything under `secrets/` or any `.env`.
That last block is the most valuable part. Every "do not" is a class of disaster the agent now can't wander into. You write it once and you stop re-explaining it forever.
Tests are the leash
The rulebook keeps the agent pointed in the right direction. Tests are what stop it from lying to you about whether it got there.
This is the single thing that makes AI coding safe past toy size: you don't trust the code, you trust the test that proves the code. So the agent doesn't get to declare victory because the diff looks reasonable. It declares victory when the suite is green, and not one second before.
In practice I either write the failing test first, or I make the agent write it before the implementation and I check that the test is actually testing the real thing (they love a test that asserts true == true and calls it a day). Then the loop is simple: red, write code, green, or back to the agent. The test is the leash. It's exactly as long as your coverage is honest.
// The contract, written before the code:
@Test
void rejectsTransferWhenBalanceTooLow() {
var account = new Account(money("10.00"));
assertThrows(InsufficientFundsException.class,
() -> account.transfer(money("25.00")));
}
// Now the agent can write transfer(). It isn't "done" until this is green.
No test, no trust. If a change can't be pinned down by a test, that's usually a sign it's the kind of change I shouldn't be handing off in the first place. Which brings up the real question.
Know what to hand over
Not everything is safe to give away, and pretending otherwise is how the velocity demos turn into incident reports.

The left column is where AI earns its keep: boilerplate, CRUD endpoints, the fifteenth mapper between two nearly identical shapes, unit tests for code that already exists, mechanical renames across forty files, "explain what this legacy function does." Work that's tedious, fast to generate, and easy to verify. Hand it over and don't feel a thing.
The right column is where I keep my hands on the wheel. System and data architecture. Anything touching auth, security, or money. Concurrency, locking, ordering, the stuff that works fine until it's 2am and a race condition is eating your weekend. And the one thing the model fundamentally can't do for you: figuring out what the actual problem is. The agent can build the thing. It can't tell you you're building the wrong thing.
The boundary isn't fixed, by the way. As your tests and your rulebook get stronger, more work safely slides left. But it slides because you earned the safety, not because you got tired of reviewing.
What the agent can't do
It can't hold your whole system in its head. It sees the files in front of it and a summary, not the four years of context about why that weird workaround exists and what breaks if you "clean it up."
It can't own the consequences. When the thing it wrote goes sideways in production, it's not on the call. You are. No skin in the game means no judgment about risk, just confident output either way.
And it doesn't know what "good" means for your domain. Good code for a banking ledger and good code for a throwaway internal dashboard are different in ways the model will flatten into the same tidy average unless you tell it otherwise.
So the senior skill in all this isn't writing code anymore. It's reading a diff quickly, smelling what's off, and saying "no, not like that" with a reason. The job shifted from typing to reviewing, and reviewing well is harder than it looks. You're the editor. The agent is a very fast, very forgetful typist.
The honest version
This makes me genuinely faster, and I'm not going to pretend it doesn't. On the 70% of the work that's mechanical, it's a different speed of working entirely. That's real, and it frees up attention for the 30% that's actually judgment, which is the part that was always worth my time.
But it is not hands-off, and the people selling it as hands-off are describing a codebase I wouldn't want to inherit. I read every diff. I write the tests, or I check the ones it wrote like I don't trust them, because I don't. The rulebook and the leash aren't bureaucracy. They're the only reason the speed doesn't turn into a slow-motion mess six months out.
The tool will change. It's Claude Code today, something better next year, and your CLAUDE.md and your test suite move over almost untouched, because they're about your codebase, not the model. That's the asset. The model is just the engine you bolt it to.
So: scope it small, write down the rules, make the tests the gate, and review like it's a junior's PR, because that's precisely what it is. Then merge it under your name and mean it.